我第一次接觸到 RAG 是在 Hello World Dev Conference 的 workshop 中。雖然 workshop 只是簡單地帶我們實作從一個 PDF 檔案中搜尋內容,但這次體驗讓我了解到目前市場上常見解決方案背後的原理。為了進一步了解 RAG 的運作方式,我決定自己實作一個小小的 side project 試試看。
RAG 是什麼?
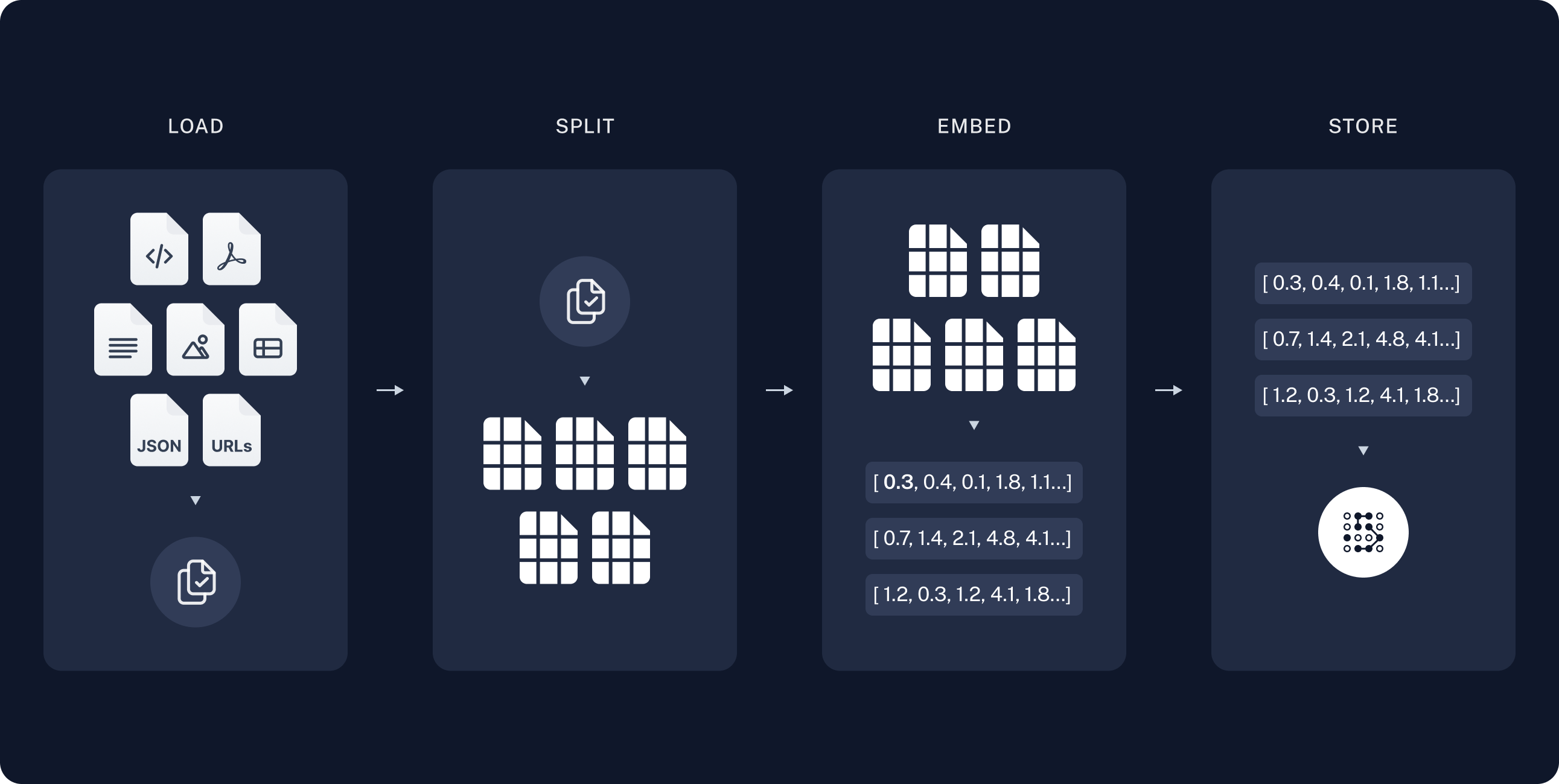
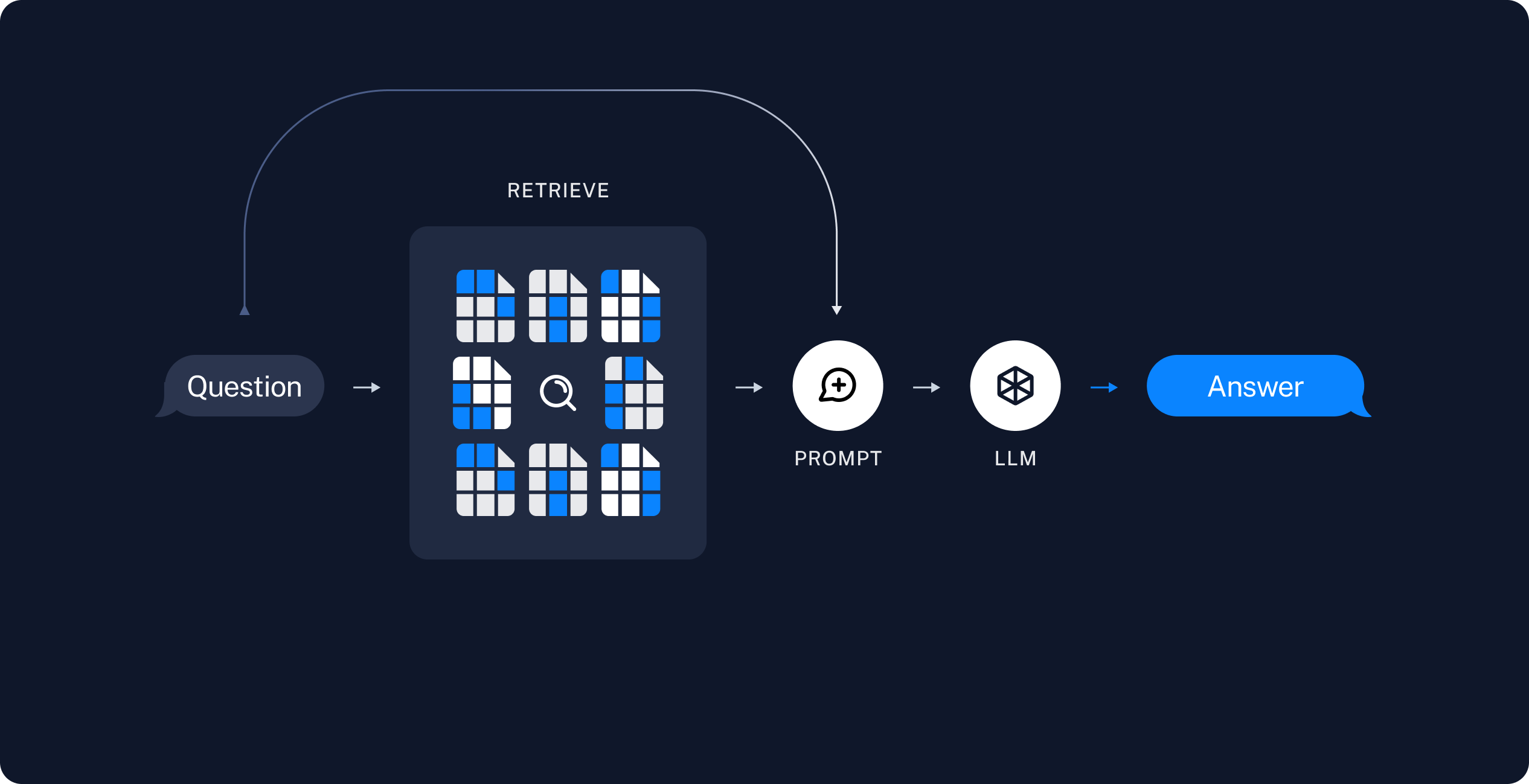
RAG,即 Retrieval-Augmented Generation,是一種結合檢索機制與生成模型的 AI 技術。傳統語言模型雖然功能強大,但其內部知識庫是固定的,可能會隨時間變得過時或不完整。RAG 透過兩個步驟解決這個問題:
檢索:從外部知識來源(例如資料庫或文件庫)中找到相關且最新的資訊。
生成:利用檢索到的資訊生成答案,確保回答準確且與當前情境相關。
這種檢索與生成的結合,使 AI 系統能產出更具時效性的答案,非常適合需要最新資訊的應用場景,例如客服支援、新聞更新或學術研究。目前,檢索步驟通常採用向量搜尋(vector search)技術來尋找相關資料。
defcombine_summaries(summaries) if summaries.size == 1 summaries.first else combined_summary = summaries.join("\n\n") summarize_summaries(combined_summary) end end
defsummarize_chunk(text) summarize_with_prompt(text, "請把下面這段文字用繁體中文總結到大約 100 字:") end
defsummarize_summaries(text) summarize_with_prompt(text, "請把下面這段文字用繁體中文總結,盡量不要遺漏太多細節:") end
defsummarize_with_prompt(text, prompt) response = @client.chat( parameters: { model: OPENAI_MODEL, messages: [ { role:"system", content:"You are a helpful assistant that summarizes text." }, { role:"user", content:"#{prompt}\n\n#{text}" } ], max_tokens: SUMMARY_TOKENS } ) response.dig("choices", 0, "message", "content") end end
sha1_hash = Digest::SHA1.hexdigest(brief_datetime_str) # to make sha1 match uuid format # https://qdrant.tech/documentation/concepts/points/ "#{sha1_hash[0..7]}-#{sha1_hash[8..11]}-#{sha1_hash[12..15]}-#{sha1_hash[16..19]}-#{sha1_hash[20..31]}" end